빅데이터 분석 기획
DIKW - 데이터 정보 지식 지혜
byte 크기 순 - 킬 메 기 테 페 엑 제 요
빅데이터의 3v - Volume Varieyl Velocity
역량 교육 체계 설계의 절차
- 요구사항 직무별역량모델검토 역량차이분석 직무역량매트릭스 교육체계설계
조직성과 평가
- 목표 설정 , 모니터링 , 목표 조정 , 평가 실시 , 결과의 피드백 순임
- 균형 성과표 (BSC : balanced Score Card) 의 4가지 관점 - 과거 성과를 바탕으로 미래 성과를 창출 (재무적 , 고객 , 업무 프로세스 , 학습과 성장) 관점
빅데이터 플랫폼
구성 요소
- 수집 , 저장 , 분석 , 활용
- 수집에는 ETL , 크롤러 , EAI 등이 있음.
플랫폼의 데이터 형식
- html , xml , csv , json
- xml 은 sgml 문서 형식을 가진 마크업 언어를 만들 때 사용하는 다목적 마크업 언어고, 태그를 사용한다.
소프트웨어
- R(시각화) , 우지 , 플럼 , Hbase , 스쿱
- 우지 는 워크플로우 관리 ! 스케줄링이나 모니터링 등등.. 맵 리듀스나 피그와 같은 액션들로 구성된 워크 플로우를 제어함.
- 플럼은 데이터 수집할 때 !- 이벤트 에이전트 활용함!!
- 분산 데이터 베이스인 Hbase 는 컬럼 기반 저장소로 HDFS 와 인터페이스를 제공함.
- 스쿱(하둡에서 관계형 디비로 데이터 보냄. 커넥터!!)은 정형 데이터 수집. sqoop , 커넥터를 사용해서 하둡 파일 시스템으로 데이터를 수집하거나 파일 시스템에서 관계형 데이터베이스로 데이터를 보내는 기능을 수행함.
분산 컴퓨팅 환경의 소프트웨어 구성 요소
- 맵리듀스
- 얀 ; 자원 관리 플랫폼
- 아파치 스피크 ; 실시간 !!!! 데이터 저장 ㄴㄴ 데이터 프로세싱 역할
- 하둡 분산 파일 시스템 ; 네임 노드 와 데이터 노드 로 이루어져있음.
- 아파치 하둡 ; 클라우드 플랫폼 위에서 클러스터를 구성해 데이터를 분석
- 하둡 에코 시스템 ; 수집,저장,처리,분석,시각화 기술로 구분이 가능함.
데이터 가공과 분석 관리를 위한 주요 기술
- 피그 , 하이브
- 피그는 맵 리듀스 api 를 단순화 시킴. sql 과 유사한 형태 , 피그 라틴이라는 자체 언어 제공
- 하이브 ; hiveQL 라는 쿼리를 제공하며 내부적으로 맵 리듀스로 변환되어 실행된다.
- 데이터 마이닝 : 머하웃 ; 하듑 기반임! 알고리즘을 구현한 오픈소스 - 데이터마이닝 알고리즘 구현한 오픈소스
개인정보 비식별 조치 - 가명 , 총계, 데이터 삭제 , 범주화 , 데이터 마스킹
- 가명처리는 휴리스틱 익명화 암호화 교환방법
- 데이터 범주화는 제어 올림 세분 정보 제한 범위 랜덤올림 범주화 기본
데이터 분석 계획
분석 로드맵 설정
분석 문제 정의
- 하향식 접근 ; 문제 탐색 먼저 ; 분석 과제가 정해져있는 거임
- 상향식 접근 ; 문제를 개선 ; 디자인 사고 접근법 ; 비지도 학습 , 프로토 타이핑(가설부터) 접근분석 기획의 유형 - 최적화 솔루션 통찰 발견
- 분석 대상과 분석 방법을 아는지 모르는지에 따라 나뉜다.
- 둘다 모르는거가 발견
- 둘다 아는게 최적화
- 방법만 아는게 통찰!
- 대상만 아는게 솔루션!분석 추진시 고려해야하는 우선순위 평가 기준
- 시급성 , 난이도
- 우선 순위 매트릭스
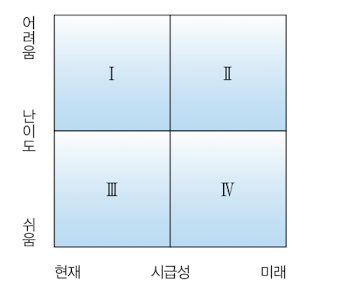
1 : 현 수준에서 과제 바로 적용하기 어렵지만 전략적 중요도가 젤 높고 시급하게 추진해야 한다.
2 : 전략도 중요도가 높지는 않지만 중장기적 관점에선 추진해야함. 난이도가 높음.
3 : 우선순위를 곧바로 적용 가능
4 : 적용은 가능하지만, 전략도 중요도는 낮다.
3 사분면 영역이 가장 우선적으로 적용 해야 한다.
빅데이터 분석 방법론의 유형
단계를 구성하는 단위활동 - 태스크 , 프로세스 그룹을 통해 산출물 생성 - 단계
- KDD 분석 방법론 : 데이터 세트 선택 - 전처리 - 데이터 변환 - 데이터 마이닝 - 평가
- CRISP-DM 분석 방법론 : 업무 이해 - 데이터 이해 - 데이터 주비 - 모델링 - 평가 - 배포
- SEMMA 분석 방법론 : 샘플링 - 탐색 - 수정 - 모델링 - 검증
데이터 수집 및 저장 계획
데이터 수집 프로세스
- 목록을 작성해야 한다. 보안 문제나 수집 가능성 여부나 세부 데이터 항목 비용 등 검토!
- 데이터 소유 기관을 파악 해야 한다.
- 데이터 유형의 구분 및 확인
- 데이터 수집 실행수집 데이터 대상
- 내부 데이터 , 외부 데이터수집 방식 및 기술
- ETL : 데이터 웨어하우스 및 데이터 마트로 이동시키기 위해 필요한 원본 데이터를 추출하고 변환해 적재하는 기술
- FTP : TCPIP 프로토콜을 기반으로 해 서버 , 클라이언트 사이에서 파일 송수신
- Sqoop : 커넥터를 활용해 관계형 데이터베이스 시스템에서 하둡 파일 시스템으로 전송
- API : 실시간 데이터 수신 가능 , 인터페이스 기술임
- RSYNC : 1:1 로 파일 과 디렉토리를 동기화 하는 응용 프로그램
- 크롤링 : 웹상 수집
- RSS : XML 기반으로 정보를 배포하는 프로토콜을 활용해 데이터를 수집
- 스크래파이 : 파이썬 기반의 애플리케이션 프레임 워크
- 아파치 카프카 : 분산 스트리밍 플랫폼 기술
- 센싱 : 센서로부터
- 스트리밍 : 네트워크
- 플럼 : 스트리밍 데이터 흐름 을 비동기 방식!!!!!
- 스크라이브 : 단일 중앙 스크라이브 , 다수의 로컬 스크라이브 서버로 구성
- 척와 : 에이전트와 컬렉터 구성을 통해 데이터를 수집하고 하둡 파일 시스템에 저장하는 기능을 제공하는 데이터 수집 기술데이터 품질 검증
- 유효성
- 데이터 정확성 - 정확성,사실성,적합성,필수성,연관성
- 데이터 일관성 - 정합성, 일치성(의미 기능 성격 등이 동일한 데이터가 상호 동일한 용어와 형태 등으로 정의 ), 무결성활용성
- 데이터 유용성 - 충분성 , 유연성 , 사용성 , 추적성
- 데이터 접근성 - 접근성
- 데이터 적시성 - 비기능적 요구사항이 잘 대처되고 있는 지
- 데이터 보안성 - 보호성, 책임성 , 안정성
HDFS 란?
hadoop distributed file system (하둡 분산 파일 시스템) - 빅데이터 관리 플랫폼;
데이터를 수집하여 활용 가능한 형태의 데이터로 관리하기 위해 수집하고 저장하고 처리, 관리 등을 수행하는 소프트웨어 플랫폼이다.
하둡 , HDFS , 맵리듀스 , Spark 등이 있다.
GFS 와 동일한 소스코드를 사용한다. 복제 횟수는 관리자가 설정할 수 있으며 네임노드는 메타데이터를 별도로 관리한다.
관리하는 2개의 마스터 노드와 처리하는 1개의 슬레이브 노드로 이루어져있다.
복제 시에는 하나의 파일을 기본적으로 3개의 서버에 복제한다.
ETL - extraction , transformation , load : 3단계를 통해 DB에 적재한다. 데이터 수집 기술 중 하나
약 인공지능 , 강 인공지능
- 약인공지능 : 주어진 조건에서만 동작
- 강인공지능 : 인간과 동일한 사고가 가능
- 약인공지능의 제한된 기능을 뛰어넘어 더 발달된 인공지능이다.
- 강인공지능은 범용으로 사용되기는 시기 상조이다.
분산 파일 시스템이란?
- 네트워크로 연결된 여러 컴퓨터에 파일을 분산 저장하고 관리하는 시스템이고, 데이터베이스가 아닌 파일을 대상으로 한다.
- 네트워크를 통한 여러 파일을 관리 및 저장하는 개념이다.
- HDFS , MapReduce , GFS 등이 있다.
- 맵 리듀스는 분산 병렬 처리 모델로 map - shuffle- reduce , input -> spliting -> mapping -> shuffing -> reducing
- 맵리듀스는 입력 데이터를 쪼개서 맵핑하고 섞은 후 분류하기 때문에 중복 제거와 합계 계산에 유용하며, 하둡에서 채택한 프로그래밍 모델이다.
- GFS 는 파일을 여러 조각으로 나누어 저장했고, 하둡에 영향을 줬음! - 동일한 소스 코드 - 쓰기보다 읽기 위주!하둡 - 오픈소스 , 빅데이터 플랫폼의 핵심 기술
- 자바 기반 프레임 워크 ,
- 분산 파일 시스템 + 맵리듀스 모듈로 구성
- 하둡은 저장과 처리의 기본적인 기능만 제공 (실시간 데이터 처리 한계 , 일괄 처리임 , 복잡한 연산 처리 한계 , 64메가바이트 이하의 작은 파일 저장 시 관리가 힘들다. 데이터 백업 낮음. 3개의 복제본 파일 관리 방식이라 디스크 공간 낭비 , 단일 고장점이 존재함- 하나 멈추면 전체 중단)
- 하둡의 기능을 보완하는 오픈소스 프로그램 등이 많이 있음.YARM - 리소스 관리 , 분산 컴퓨팅 환경 , 컴퓨팅 자원 관리 , 스케쥴링 사용 관리 , 리소스 매니저임Zookeeper - 빅데이터 서버 시스템 관리 , 분산 환경 서버들 간의 상호 조정 서비스데이터 마이닝 - Mahout분산 데이터 베이스 - Hbase (HDFS 기반의 nosql 데베) , Cassandra (컬럼 중심 DB와 행 중심 DB의 복합형, Nosql 의 하나)
- 스트리밍 데이터 - Flume , Scribe , Chuckwa
- 데이터 분석 - Hive , Pig(MapReduce 대신 자체 언어 Pig Latin 제공)
- 워크 플로우 관리 - Oozie - 하둡 작업을 관리 , 빅데이터 처리 과정을 관리
- 직렬화 - Avro - RPC 와 데이터 직렬화를 지원함.
분석 로드맵 설정 - 우선순위 선정
- 비즈니스 성관 및 ROI (return on Investment) : 투자 대비 수익률을 관점으로 함. 비즈니스 관점임. 투자비용 요소 관점 - 다양성,속도,규모
- 분석 로드맵은 분석 데이터의 적용과는 전혀 연관이 없다!
분석 시나리오 - 이해 관계자 도출 , 업무성과 판단 , 분석 목표 도출
빅데이터 분석 기획의 절차
범위 설정 - 정의 - 수행 - 위험
개인정보 비동의 시에도 사용 가능한 경우
- 법렬상 의무 준수를 위함
- 계약 체결 이행을 위해
- 정보 주체나 제 3자의 이익,생명 을 위해 필요할 시
개인 정보 법 제도 - 개인정보보호,정보통신,신용정보(개정신)
개인정보 비식별화 기술 종류
- 총계처리 , 데이터 마스킹, 가명처리, 범주화
프라이버시 보호 모델
- 익명성 , 다양성 , 근접성
빅데이터의 3V - Volume, variety,velocity : 규모 다양성 속도
4V 는 Value 추가됨!
빅데이터 활용 3대 요소는 인력,자원(데이터),기술
1 제타바이트는 2의 70 승 바이트임!
데이터 처리를 제공하는 오픈소스 종류
- 스파크 ; 인메모리 기반 - 빠른 데이터
- 맵리듀스 ; 디스크 기반
정형 vs 비정형
- 형태소는 비정형 데이터 분석을 위한 단위
고품질 데이터 특성
- 정확성 , 적시성 , 일관성 , 완전성
데이터 저장소
- 데이터 웨어하우스 , 데이터 레이크 , 데이터 댐
차등프라이버시 - 개인정보차등보호 ; 데이터 노이즈 추가해 보호 및 분석 가능하게 함.
데이터 변환 기술 - 직렬화
데이터 시각화 기술 - 가시화
데이터 저장 기술 - nosql , 비디스크 기반 DBMS , 분산 파일 시스템
- 분산 파일 시스템 - 하둡 , 구글 파일 , 아마존 S3 파일 시스템
- Nosql - 키값 모델 기반 Dynamo 이랑 Membase , 열 기반 Bigtable Hbase Cassandra , 문서 기반 couchDB MongoDB 가 있음.
- 분산 메인 메모리 기반 DBMS - SAP hana voltDb
- 플레시 메모리 활용 관리 시스템 - orcale smart flash cache 등이 있음.
데이터 처리 기술 - 맵리듀스
- 실시간 처리 , 분산 병렬 처리 , 인메모리 처리 , 인데이터베이스 처리 등의 방법
- 구글의 맵리듀스 , 하둡의 맵리듀스 , 마이크로소프트의 dryard
- 처리 프로그래밍 기술로는 sawzall, pig , 어파치 하이브 등이 있음.
데이터 접근 기술 - JDBC
데이터 분석 기술 - OLAP (online analytical processing)
- olap :
- 데이터 마이닝
- 연관 분석
- sns 분석
- 전통적 통계 분석
hadoop : 대용량 데이터를 분산 처리하기 위한 대표적인 프레임 워크
빅데이터 조직 및 인력 방안
- 집중 구조 : 중복 가능성 이 있음. 빠르게 적용 아님. 현업 부서의 다양한 요청에 신속 대응이 어려움. 현업 부서의 분석 요청이 몰리면 병목 현상이 있을 수 있음. 전사적 관점에서 분석 수행 및 표준화에 유리함.
- 기능 구조 : 직접 하는 거, 분석 결과를 협업 부서의 업무에 가장 빠르게 적용할 수 있다.
- 분산 구조 : 분석 조직 인력을 현업 부서에 배치하는 거 , 분석 결과를 협업 부서의 업무에 가장 빠르게 적용할 수 있다.
개인 정보는 정보 주체 동의 하에 원본 그대로 사용할 수 있다. 가명 익명 처리는 2차적 활용할 때 적용임.
책임 원칙 위배
- 정의: 정확한 결과를 바탕으로 책임을 지우는 기존 책임 원칙이 빅데이터의 예측 알고리즘 발달로 훼손되는 현상.
- 책임 원칙은 데이터의 수집, 활용, 결과에 대한 책임 주체를 명확히 해야 한다는 원칙.
- '빅브라더의 일상 감시'는 누가, 어떤 목적으로 데이터를 사용하는지 불투명하며, 이로 인한 피해 발생 시 책임 소재가 불분명해지는 대표적인 책임 원칙 위배 사례
총계 처리
- 특정 개인 식별 불가
- 평균 소득 은 총계 처리의 에시
- 개인정보를 안전하게 활용하기 위한 비식별조치 기술 중 하나
빅데이터 플랫폼의 계층
- 소프트웨어 , 플랫폼 , 인프라 스트럭처
- 소프트 웨어 는 데이터 처리 , 분석 , 수집 정제, 서비스 관리 , 사용자 관리 , 보안 , 모니터링
- 플랫폼 은 작업 스케쥴링 , 자원 할당 , 프로파일링 (스트럭처 자원을 할당하는 자원 , 응용 파일링 등을 수행함) ,서비스 사용자 관리 , 모니터링 , 보안 , 데이터 관리
- 인프라스트럭처 계층 - 자원 배치 , 노드 관리 , 데이터 관리 , 자원 관리 등등등
로그 스트리밍 수집 - flume , logstash
개인 정보 보호
- 가명정보 ; 추가 정보 결합 해야지 개인 식별 가능
- 익명 정보 ; 더이상 식별 불가.
빅데이터 분석
분석 주제 유형
최적화 - 모두 알 때
통찰 - 방법은 모름 ; 군집 분석 기법을 사용해서 고객을 그룹화해서 각 그룹의 특징을 발견하는 활동
해결/솔루션 - 방법은 모르는데 대상은 암
발견/탐색 - 둘다 모름.
데이터 웨어 하우스 - 주제 지향성 , 데이터 통합 , 시계열성 , 비휘발성 DW!! 정형 데이터를 저장.
강화학습
- 시행 착오를 통해 최적의 행동 학습
- Q 러닝 , SARSA 등의 알고리즘이 있다.
- 순차적인 의사결정 문제에 주로 적용된다.