[FastAPI] BackgroundTasks 심층 분석: 0.1초 응답의 비밀과 치명적 한계 (vs Celery, Custom Loop)
FastAPI를 사용하는 가장 큰 이유 중 하나는 '비동기 처리를 통한 빠른 성능'입니다.
하지만 API를 개발하다 보면 시간이 오래 걸리는 작업들을 마주하게 됩니다.
- 회원가입 환영 이메일 발송 (SMTP 통신: 1~3초)
- 이미지 업로드 후 썸네일 생성 (CPU 연산: 0.5~2초)
- 외부 API로 로그 전송 (네트워크 I/O: 가변적)
이때 사용자를 기다리게 하지 않고 "응답은 즉시(0.1초), 작업은 뒤에서" 처리하는 기술이 바로 BackgroundTasks입니다.
하지만 이 기능은 만능이 아니며, 잘못 사용했다가는 서버 전체가 멈추거나 중요한 데이터가 증발할 수 있습니다.
오늘은 BackgroundTasks의 내부 원리와 한계, 그리고 대체재(Celery, Custom Loop)와의 비교를 통해 비동기 설계를 어떤식으로 해왔는지 기록해보려 합니다!
1. BackgroundTasks의 작동 원리 (Under the Hood)
BackgroundTasks는 마법이 아닙니다. Starlette(FastAPI의 기반) 내부 구현을 살펴보면, 이 기능은 HTTP 응답(Response) 객체에 콜백 함수를 붙여두는 방식으로 동작합니다.
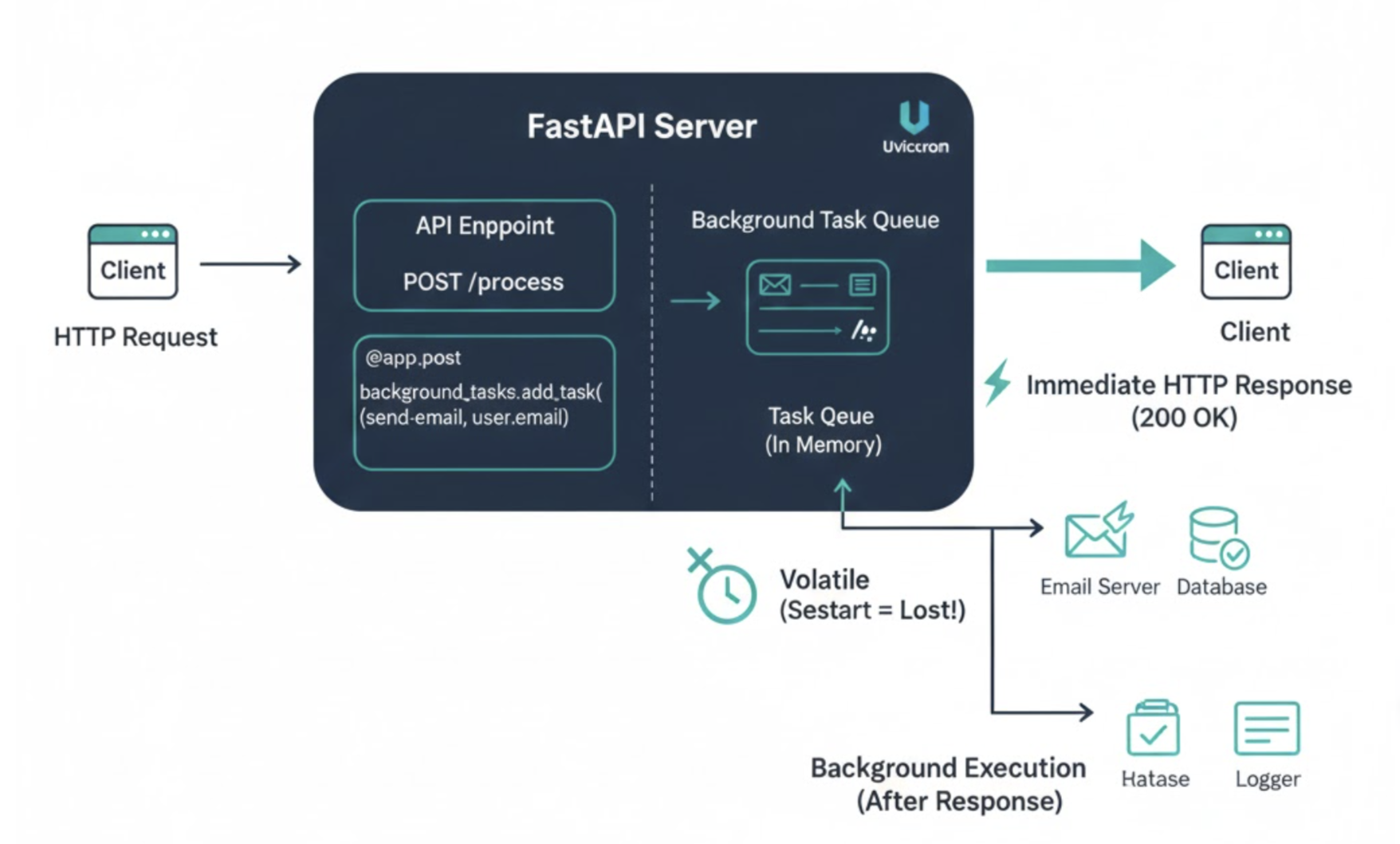
- 사용자 요청이 들어옴.
- API 로직 수행.
return Response(클라이언트에게 응답 전송 완료).- 응답 전송이 끝난 직후, 서버는 등록된
BackgroundTasks함수를 실행함.
즉, API 요청을 처리한 바로 그 프로세스(Process)와 스레드/이벤트 루프 안에서 실행됩니다. 별도의 서버나 프로세스를 띄우는 것이 아니기 때문에 설정이 매우 간편하고 가볍습니다.
아래 공식 홈페이지를 참고하면 쉽게 따라해볼 수 있음!!
https://fastapi.tiangolo.com/ko/tutorial/background-tasks/#_4
백그라운드 작업 - FastAPI
FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi.tiangolo.com
기본 사용 코드
import time
from fastapi import FastAPI, BackgroundTasks
app = FastAPI()
def write_log(message: str):
# 가상의 I/O 작업 (파일 쓰기 등)
time.sleep(1)
print(f" 로그 기록 완료: {message}")
@app.post("/order")
async def create_order(item_id: str, background_tasks: BackgroundTasks):
# 1. 비즈니스 로직 (주문 생성) - 0.01초 소요
print("주문 DB 저장 완료")
# 2. 백그라운드 작업 등록 (아직 실행 안 됨)
background_tasks.add_task(write_log, f"주문번호 {item_id} 생성됨")
# 3. 즉시 응답 반환 -> 이후에 write_log가 실행됨
return {"status": "ordered", "item_id": item_id}2. 치명적인 한계점 (The Trap)
BackgroundTasks는 '같은 프로세스 메모리'를 공유한다는 점이 장점이자 동시에 가장 큰 단점입니다.
1. 휘발성 (Volatility): 재시작하면 작업 증발
BackgroundTasks는 메모리 큐에 작업을 담아둡니다. 만약 작업이 실행 대기 중이거나 실행 중일 때 배포(Deploy)를 위해 서버를 재시작하거나, 에러로 프로세스가 죽는다면?
그 작업은 영원히 사라집니다.
- 절대 금지: 결제 확정 처리, 포인트 지급 등 돈과 관련된 작업.
- 권장: 실패해도 다시 보내면 되는 알림 메일, 단순 로그.
2. CPU 블로킹 (Blocking the Loop)
FastAPI는 기본적으로 싱글 스레드 이벤트 루프(Event Loop) 기반입니다. 만약 BackgroundTasks로 복잡한 수학 연산, 거대한 이미지 변환 같은 CPU 집약적 작업을 돌리면 어떻게 될까요?
그 작업이 끝날 때까지 서버는 다른 사람의 API 요청을 전혀 받지 못하고 멈춥니다 (Hang).
3. 재시도 로직 부재 (No Retry)
작업을 수행하다가 에러가 나면 그냥 실패하고 끝입니다.
"네트워크 오류면 3번 재시도해라" 같은 고급 제어가 불가능합니다. (직접 코드로 try-except와 루프를 짜야 함)
3. 상황별 아키텍처 비교 (Alternatives)
그렇다면 언제 무엇을 써야 할까요? 크게 3가지 선택지가 있습니다.
① FastAPI BackgroundTasks
- 구조: 현재 서버 프로세스 내 실행.
- 장점: 설정 0초. 추가 인프라 불필요. 매우 가벼움.
- 용도: "실패해도 괜찮고, 빨리 끝나는 간단한 I/O 작업" (이메일, 웹훅 호출).
② Celery + Message Broker (Redis/RabbitMQ)
- 구조: 별도의 Worker 프로세스가 작업을 수행. Redis가 중간에서 작업 큐 관리.
- 장점:
- 안정성: 서버가 죽어도 Redis에 작업이 남아있어 재시작 후 처리가능.
- 성능: API 서버와 작업 서버가 분리되어 API 속도 저하 없음.
- 기능: 재시도(Retry), 예약 실행, 모니터링 가능.
- 용도: "무겁거나(동영상 인코딩), 절대 유실되면 안 되는 작업(결제, 중요 데이터)"
③ Custom Asyncio Loop (무한 루프 워커)
- 구조:
startup이벤트에서while True루프를 실행하여 상주하는 데몬(Daemon). - 차이점:
BackgroundTasks는 요청(Trigger)이 있어야 실행됨 (Event-Driven)- Custom Loop는 요청과 상관없이 항상 깨어서 DB나 큐를 감시함 (Polling)
- 용도: "주기적으로 DB 상태를 체크하거나, 외부 소켓 데이터를 계속 받아야 할 때"
추가로!
요즘 Python 백엔드 개발의 대세는 단연 AI 서비스입니다. 그렇다면 무거운 AI 모델 추론을 BackgroundTasks로 처리해도 될까요?
"사용자가 PDF를 업로드하면, 백그라운드에서 OCR을 돌리고 벡터 DB에 저장하자!"
결론부터 말씀드리면, BackgroundTasks는 AI 모델 서빙에 절대 적합하지 않다고 생각합니당.
이유 1: GIL(Global Interpreter Lock)과 CPU 독점
AI 추론(Inference)은 대표적인 CPU/GPU 집약적 작업입니다. PyTorch나 TensorFlow가 돌아가는 동안, Python 프로세스는 막대한 연산 자원을 독점합니다. 이때 BackgroundTasks로 모델을 돌리면, 메인 스레드가 멈추면서 FastAPI 서버 자체가 '일시 정지' 상태가 됩니다. (Health Check조차 실패할 수 있습니다!)
이유 2: 메모리(VRAM/RAM) 폭발
FastAPI 워커(Uvicorn)는 보통 여러 개를 띄웁니다. 만약 각 워커 프로세스마다 BackgroundTasks로 거대 언어 모델(LLM)을 로딩한다면? 서버 메모리가 순식간에 고갈되어 OOM(Out Of Memory) Kill을 당하게 됩니다.
그럼 어떻게 해야 할까?
AI 모델은 반드시 API 서버와 물리적으로 분리된 별도의 워커(Model Worker)에서 돌려야 합니다. API 서버는 단순히 "요청"만 접수하고, 실제 무거운 추론은 Celery나 별도의 추론 서버(TorchServe 등)가 전담하도록 아키텍처를 분리해야 합니다.
4. 의사결정
실무에서 어떤 기술을 선택할지? 제 기준점인 거 같습니다! (추가적으로 저는 AI 모델을 쓰기 위해 FastAPI 를 자주 사용하기 때문에 매우매우 중요함...)
| 특징 | BackgroundTasks | Celery (Worker) | Custom Loop (Asyncio) |
|---|---|---|---|
| 실행 시점 | API 응답 직후 (1회성) | API 요청 시 큐에 적재 (비동기) | 서버 시작 시 (상시 실행) |
| 안정성 | 낮음 (서버 재시작 시 유실) | 높음 (Redis에 보존) | 낮음 (서버 재시작 시 중단) |
| CPU 부하 | API 서버와 공유 (위험) | 별도 서버/프로세스 (안전) | API 서버와 공유 (위험) |
| 설정 난이도 | 하 (코드 1줄) | 상 (Redis, Worker 설정 필요) | 중 (비동기 로직 이해 필요) |
| Best Case | 이메일 발송, 간단 로그 | 동영상 변환, 리포트 생성, 결제 | 실시간 큐 폴링, 스케줄링 |
5. 마치며
복잡한 Celery를 도입하기 전, 가벼운 프로젝트에서는 이 기능만으로도 충분한 거 같습니다...
하지만 서비스 규모가 커지고 데이터의 중요도가 높아진다면, 그때는 주저 없이 Celery나 Kafka 같은 견고한 비동기 아키텍처로 넘어가야 합니다.
다음 포스팅에서는 오늘 살짝 언급했던 [FastAPI와 AI 모델 서빙]에 대해 더 깊이 있게 다뤄보겠습니다.
Celery와 Redis를 활용해 LLM/OCR 요청을 처리하는 방법에 대해 기록해볼게욥!
'ServerDev > FastAPI' 카테고리의 다른 글
| [FastAPI] 미들웨어 - 작동 원리부터 ELK 연동을 위한 JSON 구조화 로깅까지 (0) | 2025.12.13 |
|---|---|
| [FastAPI] 미들웨어(Middleware) - 개념부터 커스텀 구현까지 (0) | 2025.12.12 |
| [FastAPI - CORS 마스터 3부] 개발(Local) vs 운영(Prod) 환경 분리와 실전 트러블 슈팅 (0) | 2025.12.12 |
| [FastAPI - CORS 마스터 2부] 쿠키 인증(Credential) 이슈 해결과 보안을 위한 정교한 허용 전략 (0) | 2025.12.11 |
| FastAPI - CORS 마스터 1부] 프론트엔드 연동 첫걸음, CORS 에러 (0) | 2025.12.10 |