이번에는 서버 운영을 맞춰, 설계한 파이프라인에 대해 글을 써보려고 합니다!

처음에는 FastAPI 하나에 OCR 로직까지 모두 넣어서 빠르게 기능을 구현했습니다.
(원래는 Redis + Celery 로 워커를 도입하려 했는데, 초기 PoC 단계에서는 추후 구현으로 둬야된다 하셔서 FastAPI 하나에 임베딩 모델 , OCR 로직도 나 넣었음... )
하지만 실제로 서버를 운영해보니, 이 구조로 발생했던 문제가 Requirement 를 Docker 이미지에 설치하는데에서 발생하더라구요,
기존에 FastAPI 는 서비스 레이어 로직 정도로만 구현해놨었고, Worker 를 따로 분리할 생각이었어서 ML 에 익숙한 라이브러리를 선택하는 것 보다 서비스 레이어 딴에 맞춰진 라이브러리들로 구성을 해놨었습니다. 다만, OCR 을 따로 모듈로 만들어 함수화로 해 import 할 때 각각 독립적으로는 잘 돌아갔지만, 하나의 이미지로 빌드를 하려는 순간 충돌이 발생해버려서...
NumPy, Torch, OpenCV, PaddleOCR 등 서로 다른 요구 조건을 가진 라이브러리들이 한 컨테이너 안에 들어가면서, 버전 충돌과 빌드 실패가 반복적으로 발생했음.
이 문제는 단순히 라이브러리 버전을 맞추는 것으로는 해결되지 않았고, 결국 “구현 문제”가 아니라 서버 역할 분리 문제라는 결론에 도달.... (해당 라이브러리 버전 충돌은 추후 다른 장에서 다루겠습니다.)
OCR은 GPU를 사용하고, 무거운 라이브러리(PaddleOCR, OpenCV, PyMuPDF 등)를 필요로 하기 때문에 API 서버와 같은 프로세스 안에서 함께 돌리기에는 부담이 컸기 때문입니다.
그래서 이후에는 접근 방식을 완전히 바꾸게 되었습니다.
API 서버는 요청을 받고 상태를 관리하는 역할에 집중시키고, OCR 처리는 별도의 워커 서버에서 전담하도록 분리하는 구조로 파이프라인을 재설계하게 되었습니다. 다만, 기존에는 Redis로 분리를 하려 했지만, Poc단계에서는 적합치 않은 듯 해 API 호출형식으로 구현을 해야겠다 생각을 했습니다.
Redis + Celery를 써야 되는 이유는 Task 처리 방식 때문이기도 한데, 그것을 API 로 관리를 하려 합니다.
왜냐하면 이번 구조에서는 Task를 무작위로 분산 처리하는 것이 목적이 아니라, “OCR이라는 명확히 무겁고 오래 걸리는 작업을 API 서버로부터 분리하는 것”이 핵심이었습니다.
즉, 큐잉 자체보다도 서버 역할 분리와 리소스 보호가 더 중요한 상황이었습니다.
그래서 PoC 단계에서는 Redis를 중간에 두는 대신, API 서버가 워커 서버에 명시적으로 OCR 작업을 요청하는 API 호출 방식으로도 충분히 논리적인 구조를 만들 수 있겠다고 판단했습니다.
이 방식이 성립하는 이유는, OCR 작업이 다음과 같은 특성을 가지기 때문입니다.
- 요청 단위가 명확하다 (jobId, fileId 기준)
- 실시간 응답이 필요 없다
- 처리 시간이 길고, 결과는 나중에 조회해도 된다
- API 서버가 “상태 관리의 주체”가 될 수 있다
즉, API 서버는 단순히 요청을 중계하는 역할이 아니라, 작업의 생명주기(job lifecycle)를 관리하는 컨트롤 타워가 됩니다.
이 구조로 서버를 분리하게 되면, 자연스럽게 몇 가지 문제가 발생합니다.
첫 번째는 세션 꼬임 문제입니다.
유저가 OCR 요청을 보냈을 때, 해당 요청이 워커 서버로 넘어가고 다시 결과가 돌아오는 과정에서 “이 결과가 어떤 유저의 요청이었는지”를 정확히 매칭해야 합니다. 만약 이 연결이 흐트러지면, 잘못된 유저에게 결과가 전달되거나 상태 조회가 불가능해질 수 있습니다.
이를 해결하기 위해 API 서버는 모든 OCR 요청에 대해 jobId를 발급하고, 이 jobId를 기준으로 상태를 관리합니다.
워커 서버는 세션이나 유저 정보에 대해 전혀 알 필요가 없고, 오직 jobId와 파일 경로만 받아 처리한 뒤 결과를 다시 API 서버에 전달합니다.
즉,
- 세션 관리 → API 서버 책임
- OCR 처리 → 워커 서버 책임
으로 역할을 명확히 나눔으로써, 세션 꼬임 문제를 구조적으로 차단하게 됩니다.
두 번째 문제는 GPU 및 메모리 오버헤드입니다.
OCR 모델은 초기 로딩 비용이 크고, GPU 메모리를 상당히 점유합니다. 만약 API 서버에서 직접 OCR을 수행하게 되면, 요청 수가 늘어날수록 모델 로딩, VRAM 점유, 메모리 사용량이 급격히 증가하게 됩니다.
특히 여러 유저가 동시에 요청을 보낼 경우,
- 모델이 프로세스별로 중복 로딩되거나
- GPU 메모리가 한계에 도달해 OOM이 발생하거나
- API 서버 전체가 응답 불능 상태가 되는 문제
가 발생할 수 있습니다.
이를 방지하기 위해 OCR 워커 서버에서는 프로세스 수와 동시 처리 수를 명시적으로 제한하려 합니다.
예를 들어 GPU를 사용하는 워커 프로세스를 2개만 띄우고, 각 프로세스 내부에서 동시에 처리할 수 있는 작업 수를 제한함으로써, VRAM 사용량을 예측 가능한 범위로 통제할 수 있습니다.
결과적으로,
- API 서버는 가볍고 안정적으로 유지되고
- OCR 워커는 GPU 리소스를 독점적으로 관리하며
- 전체 시스템은 요청 폭주 상황에서도 무너지지 않는 구조
를 만들면 되겠다! 싶었습니다.
이러한 이유로 PoC 단계에서는 Redis + Celery 대신, API 기반 워커 호출 + 명시적 상태 관리 구조를 선택하게 되었고,
이후 트래픽 증가나 재시도, 스케줄링이 필요해질 경우 Redis 기반 구조로 확장할 수 있도록 설계를 열어두었습니다.
다만, 여기서 추가적으로 마주하게 된 문제는 현재 운영 중인 서버들의 GPU 상황을 함께 고려해야 한다는 점이었습니다.
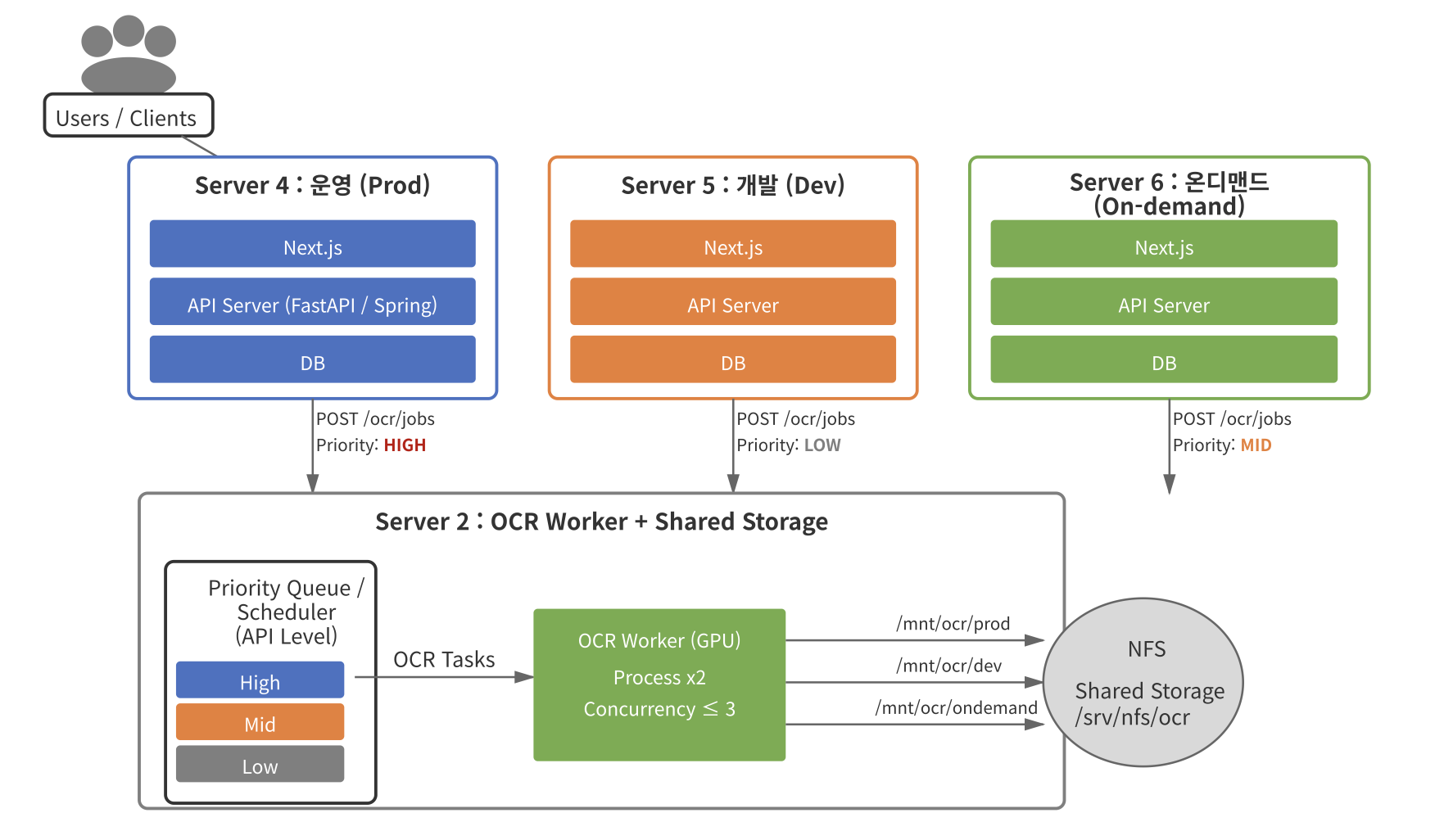
현재 서버는 총 네 대로 구성되어 있었고,
한 대는 클라우드 운영용, 한 대는 개발용, 한 대는 온디맨드 주문용, 그리고 한 대는 별도 작업용 서버로 사용하고 있었습니다.
각 서버에는 백엔드(Spring), FastAPI, vLLM, Next.js, DB 등 하나의 서비스를 운영하는 데 필요한 모든 구성 요소가 함께 올라가 있는 상태였습니다.
이 구조에서 문제가 된 것은,
이번에 선택한 Paddle OCR 모델이 GPU를 생각보다 많이 사용한다는 점이었습니다.
특히 추론 자체보다도 모델 로딩 시점에서 GPU 메모리를 상당히 점유한다는 점이 운영 관점에서는 꽤 치명적으로 다가왔습니다.
만약 각 서버마다 OCR 워커를 띄우게 되면, 서버마다 동일한 OCR 모델이 중복 로딩되고 각 서버의 VRAM이 빠르게 소모되며 기존에 이미 GPU를 사용 중인 vLLM, 추론 서버들과 리소스 충돌이 발생할 가능성이 높아집니다.
(우선 순위를 선택한다해도, 빠른 답변이 중요한데 GPU 의 전체 할당량 보다 많은 요청이 들어올 시 vLLM 이 가장 우선이 되어야 하지만, 그럼 OCR 자체의 응답이 매우 지체됨..)
즉, “기능적으로는 가능하지만 운영적으로는 위험한 구조”가 되어버리는 상황이었습니다.
그래서 생각해낸 방안이 Ocr을 돌리는 워커는 서버 한대에만 올리고, 다른 서버들의 모든 Ocr 요청을 해당 서버에 가게끔 포트 포워딩을 해야겠다로 결론이 났습니다. (물론 추후 온디맨드 온프레미스형 실 운영 서버 시에는 해당 서버에 올려야 되지만요..)
현재로선 PoC 및 운영 환경에서는 GPU 리소스를 중앙 집중식으로 관리하는 것이 가장 현실적인 선택이었습니다.
다만 여기서 또 하나의 문제가 발생합니다. 운영 서버, 개발 서버, 온디맨드 서버 세 곳의 모든 OCR 요청이 하나의 서버로 몰리게 되면, 요청 처리 지연이 발생할 수밖에 없다는 점입니다.
특히 운영 관점에서 보면, 운영(클라우드) 서버 요청은 가장 우선 처리되어야 하고 개발 서버 요청은 상대적으로 지연되어도 괜찮은 요청입니다. 하지만 단순히 포트 포워딩만으로 모든 요청을 동일하게 OCR 워커로 보내게 되면, 이러한 우선순위 개념을 적용할 수가 없습니다.
그래서 “단순히 요청을 보내는 구조”가 아니라, 요청을 한 번 더 정리하고 조절할 수 있는 레이어가 필요하겠다는 판단을 하게 되었습니다.
(다서버 3대의 모든 요청이 하나의 서버에 있는 Ocr Worker 로 몰릴 시 제가 볼때는 운영이 1순위, 그다음이 개발이라 판단했음.)
즉, 바로 OCR 워커로 보내는 것이 아니라 한 번 대기 큐에 쌓고 요청의 출처(운영 / 개발 / 온디맨드)에 따라 처리 우선순위를 조절하는 구조가 필요해졌습니다.
이 지점에서 자연스럽게 “Task Queue” 개념이 등장하게 되었고, 비록 Redis + Celery를 사용하지는 않았지만, 논리적으로는 Task Queue와 동일한 역할을 API 레벨에서 구현하는 방향으로 설계를 확장하게 되었습니다.
그리고 또한, 원래는 서버 한대에서 모든 네트워크 선을 탈 때는 볼륨 마운팅 설정만 하면 됐었는데, 현재는 서버가 분산 되어있기 떄문에 공유 스토리지를 구현을 해야 겠구나를 생각했습니다.
즉, OCR 워커 서버와 API 서버들이 같은 파일을 바라볼 수 있는 공유 스토리지가 필요해졌습니다.
이 지점에서 자연스럽게 공유 스토리지 설계와 보안 문제가 함께 따라오게 됩니다. 여러 서버가 하나의 스토리지를 함께 사용한다는 것은, 단순히 디렉토리를 마운트하는 문제를 넘어 권한 관리, UID 통일, root 권한 처리, 접근 제어 등 운영 관점에서 반드시 고민해야 할 요소들이 많다는 뜻이기도 합니다. 다만 이 부분은 아키텍처 설계 못지않게 중요한 주제이기 때문에, 이번 글에서는 개념적인 흐름까지만 다루고, 다음 글에서 NFS 기반 공유 스토리지 설계와 보안 설정을 운영 관점에서 자세히 정리해보려 합니다.
( 물론 API 요청 시 파일을 바이트 스트림으로 직접 전달하는 방식도 고려할 수 있었지만,, OCR 파일은 크기가 크고, 처리 시간이 길며,
중간 단계 결과까지 관리해야 하는 특성상 네트워크를 통해 파일을 매번 전달하는 방식은 비효율적이라고 판단했음. 실제로 비효율적인지는 비교해봐야 될듯...이건 다음에 진행해보려구요 )
최종적으로 파일은 공유 스토리지(NFS)에 저장하고 API 서버와 OCR 워커가 동일한 경로를 바라보도록 구성하는 방식!
결과적으로 이 단계에서의 설계는 단순히 “기능 구현”이 아니라,
GPU 자원 보호, 요청 우선순위, 서버 역할 분리, 운영 안정성을 모두 고려한 구조로 설계해보려 합니다.