최근 인턴 활동을 하며 회사 내의 폐쇄형 LLM 을 모델로 사용해, RAG 를 구축한 챗봇 서비스에 투입 되어 일을 맡고 있습니다. 어떤 아키텍처가 적합할지 고민을 하다가 제가 지금까지 어떤식으로 아키텍처를 설계해왔는지 AI 모델 서빙과 관련해 정리를 해볼까 합니다. (원래 하이브리드 서버 를 좋아하는 편이라 더 적합하지 않는 것일 수도 있어요 .. 하지만 정리는 좋은 거니까! )
단순 AI 모델 서빙이라면 SpringBoot + FastAPI , 또는 Only FastAPI 로도, 이 구조만으로도 80%의 요구사항은 해결된다 생각하긴 합니다. 텍스트 감성 분석, 간단한 추천 시스템, 데이터 전처리 같은 작업은 HTTP 요청 한 번으로 충분하죠.
하지만 서비스가 성장하고 요구사항이 고도화되면, 우리는 '벽'에 부딪힙니다.
- "생성형 AI 모델이라 응답이 1분이나 걸리는데, 사용자가 기다려 줄까요?"
- "LLM을 도입하려는데, 프롬프트 관리는 어디서 하죠?"
- "트래픽이 폭주해서 GPU 서버 비용이 감당이 안 됩니다."
- "단순한 기능인데 굳이 서버를 두 개나 띄워야 하나요?"
- "AI API 연결인데, 세션이 꼬이진 않나요?"
오늘은 이러한 구체적인 문제점들을 해결하기 위해, 제가 어떤식으로 아키텍처를 고민해왔고 선택했는지, 기본 아키텍처를 어떻게 변형하고 확장해야 하는지 5가지 실전 패턴을 통해 깊이 있게 파헤쳐 보겠습니다.
상황 1: "응답이 너무 느려요" (Generative AI)
해법: 비동기 메시지 큐 (Async Queue) 패턴
최근 유행하는 Stable Diffusion(이미지 생성)이나 고화질 Video Upscaling 같은 작업은 추론에 짧게는 수 초, 길게는 수 분이 걸립니다.
이걸 기존처럼 동기식(Synchronous) HTTP 요청으로 처리하면 대참사가 벌어집니다.
- Spring의 스레드가 응답을 기다리며 블로킹(Blocking)됩니다.
- 사용자 브라우저에서 'Time-out' 오류가 발생합니다.
- 중간에 있는 Nginx나 로드밸런서가 연결을 끊어버립니다.
이때는 "일단 접수만 받고, 결과는 나중에 줄게" 전략으로 가야 합니다.

아키텍처 설계
- Spring Boot (Producer)
- 사용자의 요청을 받자마자 Kafka나 RabbitMQ 같은 메시지 큐에 작업을 던집니다.
- 그리고 사용자에게는 즉시
202 Accepted와 함께ticket_id를 반환합니다. "접수되었으니 기다리세요."
- Message Queue
- Spring과 FastAPI 사이의 완충재 역할을 합니다. 요청이 폭주해도 큐에 쌓아두면 되니 서버가 죽지 않습니다.
- FastAPI (Consumer/Worker)
- 백그라운드 워커(Celery 등)가 큐에서 메시지를 하나씩 꺼내 무거운 모델을 돌립니다.
- 작업이 끝나면 결과 이미지를 S3에 업로드하고, DB에 "작업 완료" 상태를 업데이트합니다.
- (옵션) 완료 시 Spring에게 Webhook을 날리거나, 사용자의 WebSocket으로 알림을 보냅니다.
상황 2: "간단한 기능인데 너무 복잡해요" (MVP)
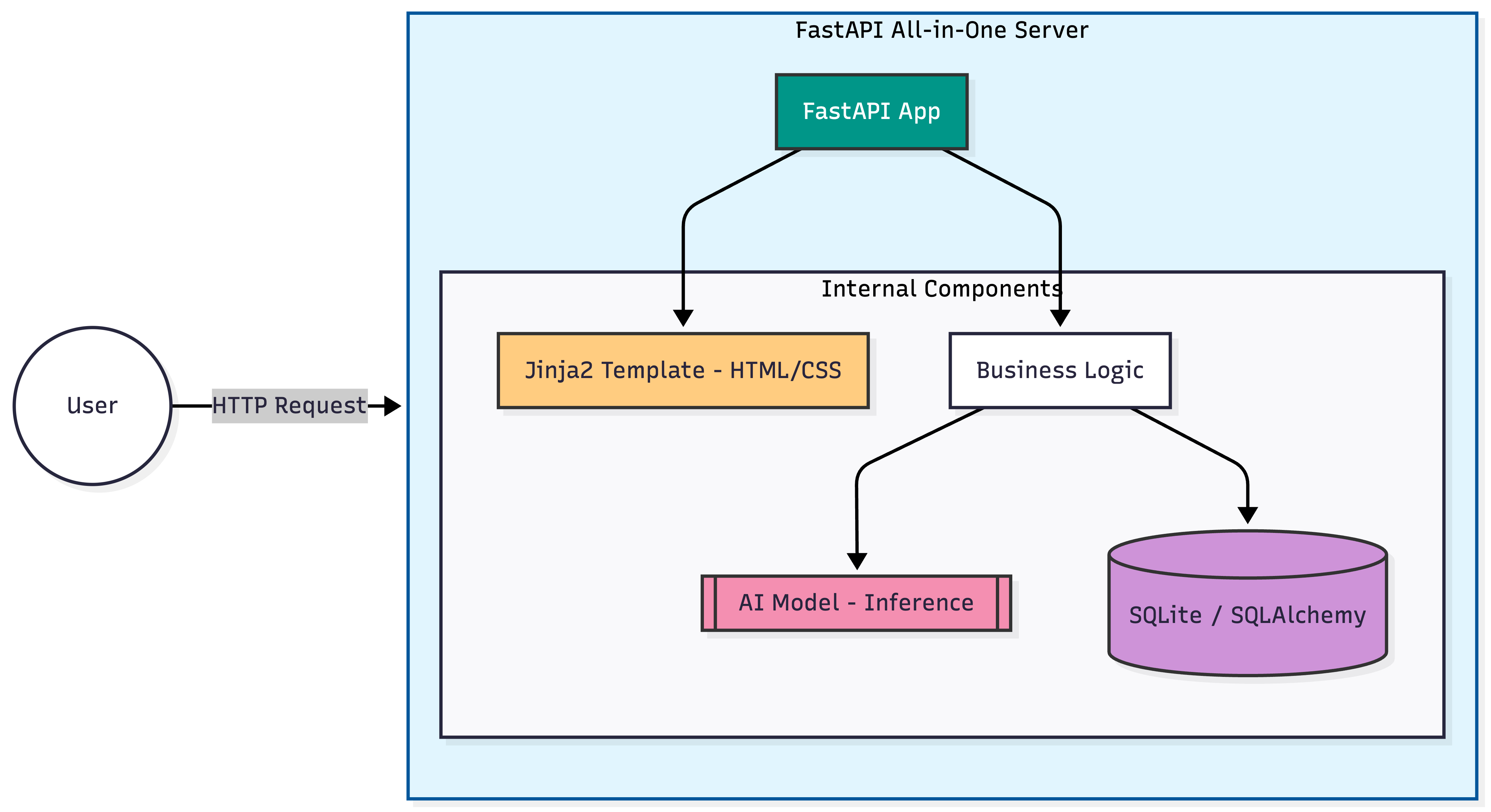
해법: FastAPI All-in-One 패턴
모든 프로젝트를 거창하게 시작할 필요는 없습니다. 예를 들어, "사진을 올리면 배경을 지워주는 간단한 툴"을 만든다고 가정해 봅시다.
유저 로그인도 필요 없고, 결제도 없고, 단순히 기능 하나만 보여주는 MVP(Minimum Viable Product)입니다. 여기에 Spring Security 붙이고, JPA 설정하고, FastAPI 따로 띄우고... 이건 명백한 오버 엔지니어링(Over-engineering)입니다.
아키텍처 설계
- Only FastAPI Spring Boot를 과감하게 제거합니다.
- 구현
- FastAPI 하나로 HTML 렌더링(Jinja2)부터 모델 추론까지 다 처리합니다.
- DB가 필요하다면 가벼운 SQLite나 SQLAlchemy를 바로 붙입니다.
- 배포도 Docker 컨테이너 하나면 끝납니다.
Insight
서비스가 커져서 복잡한 비즈니스 로직이 필요해지면 그때 Spring을 앞단에 붙이면 된다고 생각합니다. 아니면 FastAPI 로 구현해도 되구요. AI 모델이 들어간 서버에서는 "속도" 가 가장 중요하니깐요...
4. 상황 3: "초당 1만 건, 속도가 생명입니다" (High Traffic)
해법: 전용 인퍼런스 서버 (Triton/TorchServe) 패턴
서비스가 대박이 나서 트래픽이 폭주하기 시작했습니다. 그런데 Python 기반의 FastAPI가 병목을 일으킵니다. Python의 GIL(Global Interpreter Lock) 때문에 멀티코어를 제대로 못 쓰거나, 처리 속도가 C++에 비해 느리기 때문입니다.
이때는 모델 서빙의 주체를 Python에서 C++로 최적화된 전문 서버로 넘겨야 합니다.
아키텍처 설계
- Spring Boot여전히 비즈니스 로직을 담당합니다.
- FastAPI (Gateway) 모델을 직접 돌리지 않습니다. 요청을 검증하고, 전처리(이미지 리사이징 등)만 수행한 뒤, Triton에게 토스합니다.
- NVIDIA Triton Inference Server
- NVIDIA에서 만든 고성능 추론 서버입니다.
- Dynamic Batching: 동시에 들어온 여러 요청을 모아서 한 번에 GPU에 태웁니다. (처리량 급상승)
- 모델을 C++ 레벨에서 실행하므로 Python보다 압도적으로 빠릅니다.
이 구조에서 FastAPI는 무거운 짐을 내려놓고, 아주 얇고 빠른 'AI 게이트웨이' 역할만 수행하게 됩니다.
5. 상황 4: "우리 회사만의 ChatGPT가 필요해요" (Private LLM)
해법: LLM 게이트웨이 & Ollama 패턴
보안 문제로 OpenAI API를 쓸 수 없어, 사내 서버에 Llama 3나 Mistral 같은 오픈소스 LLM을 구축해야 하는 상황입니다.
이때 가장 쉬운 방법은 Ollama를 사용하는 것입니다. 하지만 Spring에서 Ollama API를 날것 그대로 호출하면 유지보수가 힘들어집니다. 프롬프트는 텍스트 덩어리라 관리가 어렵고, 히스토리(Context) 관리도 복잡하기 때문입니다.
(근데 더 적절한 아키텍처 설계가 있을 거 같다는 생각이 듭니다.. Ollama 를 사용해본 적이 없어서 좀 찾아보니, 생각보다 동시 접속자에 대한 처리와 지연이 명확하지는 않더라구요. 병목 현상이 발생하는 것 같다는 생각이 드는데,, 아직 테스트는 해보지 않았습니다. VLLM 은,, 사실 Ollama의 병목현상 처리만 잘 하면 굳이 싶기도 합니다. 최대 몇명까지가 수용 되는지 확인해보고 싶네요..)
아키텍처 설계
- Spring Boot
- 사용자의 질문("이 문서 요약해줘")만 깔끔하게 보냅니다.
- FastAPI (Prompt Engineer)
- 프롬프트 주입: 사용자 질문 앞뒤로 "You are a professional summarizer..." 같은 시스템 프롬프트를 붙입니다.
- RAG (검색 증강): 필요하다면 벡터 DB(ChromaDB 등)에서 관련 문서를 찾아 프롬프트에 끼워 넣습니다.
- LangChain 활용: 파이썬의 강력한 LLM 라이브러리들을 활용해 체인을 구성합니다.
- Ollama
- 완성된 프롬프트를 받아 추론만 수행하고 결과를 스트리밍합니다.
FastAPI가 중간에서 '통역사' 역할을 해주는 덕분에, Spring 개발자는 복잡한 프롬프트 엔지니어링에서 해방될 수 있습니다.
6. 상황 5: "GPU 비용이 줄줄 새고 있어요" (Cost Optimization)
해법: Serverless AI (K8s & KServe) 패턴
가장 현실적인 문제입니다. 모델이 10개인데, 사용자가 뜸한 새벽 시간에도 비싼 GPU 인스턴스 10대를 켜둬야 할까요? 회사 입장에서는 돈을 태우는 일입니다.
이때는 Kubernetes(K8s)와 KServe를 도입하여 Serverless(서버리스) 환경을 구축해야 합니다.
아키텍처 설계
Scale-to-Zero (0으로 축소)
- KServe는 요청이 없으면 파드(Pod) 개수를 0개로 줄입니다. GPU를 점유하지 않으니 비용이 0원입니다.
- 요청이 들어오는 순간(Cold Start), 자동으로 파드를 띄워 응답합니다.
- Canary Deployment
- 모델 버전 1과 버전 2를 동시에 띄우고, 트래픽의 10%만 버전 2로 보내는 테스트를 설정 파일 하나로 할 수 있습니다.
이 단계는 인프라 복잡도가 높기 때문에, 모델의 개수가 많고 트래픽 변동이 심한 엔터프라이즈 환경에서 추천합니다.
마치며: 아키텍처는 생물이다
제가 소개한 5가지 패턴 중 정답은 없습니다. 다만 이런식으로 설계하면 좋지 않을까? 이런식으로 설계할 수도 있구나를 깨달은 것 같습니다. 여러 실무를 접하며 또 다른 , 적합한 아키텍처를 설계하는 능력을 얼른 가지고 싶습니다...